6
Şifre stratejisinde 4 gereksinim vardır. Aşağıdakilerden herhangi birini aşağıdakiDört normal gereksinimden en az üçünü eşleştirmenin en iyi yolu
- küçük harf içermelidir.
- büyük harf.
- sayısal.
- özel karakter. '|'
aşağıdaki regex Ben kullanabilirsiniz bildiğim vakası,
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[^a-zA-Z0-9]).{4,8}$
maç olacak Ancak, tüm kombinasyonları ilan etmek için, akşam yemeği uzun bir normal ifade üretecektir. '|' Ile değiştirmenin en iyi yolu nedir? Böylece, girdinin kombinasyondaki üç koşuldan herhangi birini içerip içermediğini kontrol edebilir mi?
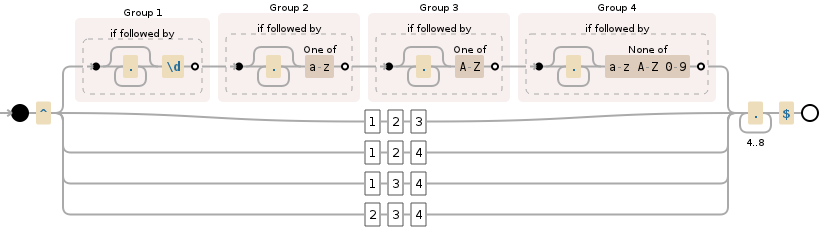
Şunu Bu '^ (= * [_ (= * \ D?.) (= * [A-Za-z]?.?).? \ W]). {4,8} ' –
Neden sadece okunabilirlik için basit tutmak ve 4 farklı regex kullanmak? – Wolph
benim için net değil. Bazı geçerli ve geçersiz eşleşmeler sağlayabilir misiniz? –