Python ve NLP dünyasında yeniyim. Google'ın Syntaxnet'inin son duyurusu beni şaşırttı. Ancak etrafında sorun anlama belgelerin bir yaşıyorum syntaxnet ve ilgili araçlar (nltk, vs.) hemSyntaxNet Kök ağacına fiil oluşturma
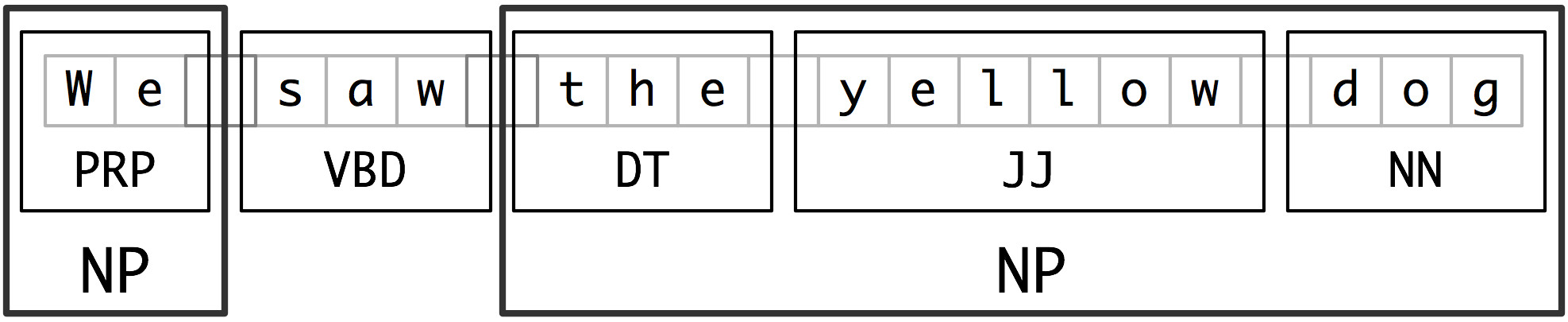
Amacım: Ben kök fiil ayıklamak istiyorum "Wilbur topu tekmeledi" gibi bir giriş verilmiş (tekme) ve nesne "top" ile ilgilidir.
ben "spacy.io" tökezledi ve this visualization ben başarmaya çalışıyorum neyi saklanması görünüyor: Ben kök fiil başlar ve çapraz böylece POS etiketi bir dize ve ağaç yapısı çeşit içine yüklemek cümle.Syntaxnet/demo.sh ile oynandım ve this thread'da önerildiği gibi, conll çıkışı almak için son birkaç satırı yorumladı.
Sonra (muhtemelen düzeltmez birlikte kludged kendimi) bir python komut dosyası bu girişi yüklenen:
import nltk
from nltk.corpus import ConllCorpusReader
columntypes = ['ignore', 'words', 'ignore', 'ignore', 'pos']
corp = ConllCorpusReader('/Users/dgourlay/development/nlp','input.conll', columntypes)
ben corp.tagged_words() erişimi olduğunu görüyorum ama sözcükler arasında hiçbir ilişki. Şimdi sıkıştım! Bu corpus'u ağaç tipi bir yapıya nasıl yükleyebilirim?
Herhangi bir yardım çok takdir edilmektedir!
{kind=link}
Bana göre ayrıştırma parçasını kaçırdınız. Verilerinizi önceden kaydettikten sonra, ham metni, POS etiketini belirtin ve bunu birleşik biçime dönüştürün, onu ayrıştırıcıya iletmeniz gerekir (sizin durumunuzda SyntaxNet). Sonra, ayrıştırıcı çıktısında istediğiniz herhangi bir çıkarma işlemini yapabilirsiniz. – Riyaz